
🎯 Research Objective
My primary research goal is to improve the generalization of machine learning systems. This can be summarized by the phrase, “You get what you train for.” An incorrect objective will lead to poor generalization, even when a large amount of data is applied to a problem. My research focuses on defining the correct objectives, thereby improving the ability of machine learning models to generalize effectively.
For instance, current state-of-the-art generative models often fail to generate an image of “a red polar bear” or edit the color of a polar bear in an image without changing other aspects. Why do current SOTA models struggle? The objective of diffusion models is to learn the probability of the observed data distribution. However, in the observational data, these seemingly independent concepts of color and animal structure are rather dependent. Therefore, if you are modeling the incorrect observational data, you are bound to get a model that is incorrect. In our ICLR 2025 work, we correct the training objective of diffusion models to reflect the independence that allows us to modify one attribute without affecting the others.
Classical machine learning algorithms are also prone to generalization problems. Models such as SVM and LDA rely on spurious features for classification. In Pattern Unrecognition work, we provide a modified objective that is invariant to spurious features. This objective transforms the problem into a generalized eigenvalue problem with a closed-form solution.
Algorithmic fairness is another area where an appropriate training objective should include a constraint on fairness, ensuring that models do not base decisions on sensitive attributes like gender. I have studied constrained optimization, and this work resulted in my research notes on Constrained Optimization and Min-Max Problems. Additionally, I proposed a pre-processing adversarial pipeline to improve fairness in LLMs. On a fun side, classic dynamic problems can be formulated as constrained optimization, and projected gradient descent can get you an approximate solution faster.
I also care about the impact of ML and have worked on practical problems such as how to train with large-scale multi-modal data with imbalance. Also in P-GPT. I strive to find the efficient configuration for training across multiple servers.
I used to work on Adversarial Machine Learning. I’m no longer interested in this area, although the optimization techniques are useful; it’s always a catch-up game. However, I have written a blog post on How to solve an Adversarial Optimization Problem?. Also, Machine Unlearning: This involves removing training data from the model. I’m no longer interested in unlearning as I struggle to understand a metric to quantify it. However, we participated in the NeurIPS 2023 challenge on Machine Unlearning
Adversarial Techniques for Improving Fairness in LLMs
 | Large Language Models (LLMs) have experienced a surge in popularity in recent times, owing to their remarkable ability to follow instructions and demonstrate success across a wide range of Natural Language Processing (NLP) tasks. However, LLMs suffer from a wide range of issues such as harmful generation, fairness, privacy, and robustness. Addressing these issues provides immense value to society and also ensures responsible use of technology. These issues can be classified as adversarial tasks, where the goal of the adversary is to trigger wrong behavior, and LLMs should be robust to such attacks. We collate recent advances in adversarial techniques in the survey paper. We address the discrete inputs with Gumbel softmax reparametrization trick and instability with stochastic weight averaging (SWA), and we leverage LoRA adapter to account for the large memory and compute required to train LLMs. |
Parallel GPT
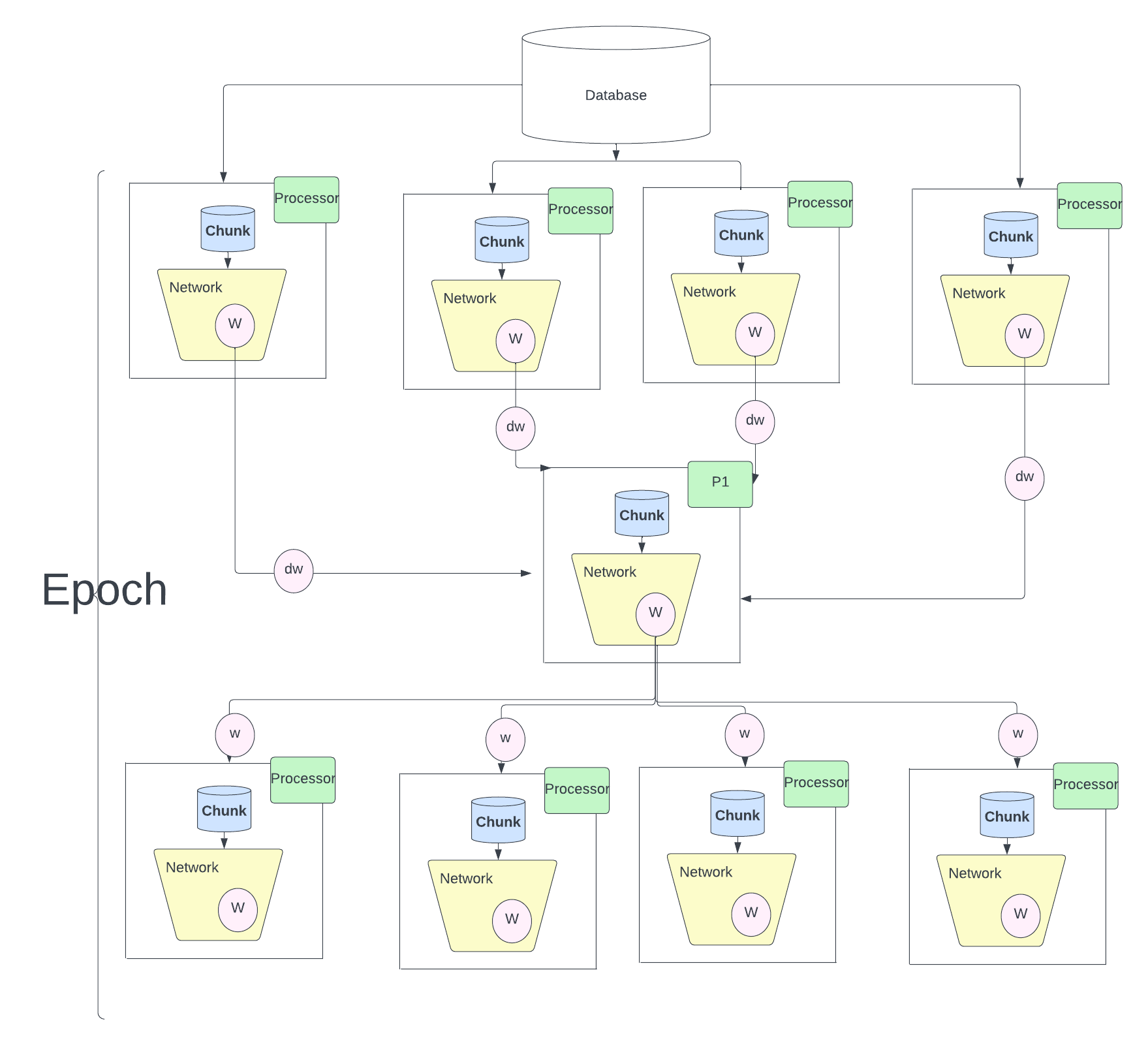 | We all know the impact of of chatGPT which are trained on massive internet data. The success of ChatGPT can be attributed to the amount we can parallelise, In fact the idea of Attention mechanism which is the crux of GPT was designed to overcome the sequential algorithm LSTM. Once we make the network parallel both the model and data parallel we can leverage the huge amount of data and train massive compute intensive algorithms.In this work, I will use model one attention block, which would constitute the fundamental element of the GPT. I will analyse the efficiency of the parallel strategies and uncover the reasons behind such numbers. Test some of the asymptotic limits of the parallel strategies and will raise some comments on the parallel strategies we have used. you will find the explanations on why we have chosen a particular strategy. |
Pattern Unrecognition
 | Large models can accurately model complex decision boundaries but may not generalize well to new or out-of-distribution samples. This is a challenge for autonomous cars because it’s impossible to collect data from every road in the world. Researchers - Ribeiro et.al and Arjovsky et.al - have studied the problem of spurious correlations in image classification, where, for example, wolves are more likely to be spotted in snowy backgrounds than dogs. We want to know how well current classification techniques address this issue and propose new ideas to overcome spurious correlations. |
Machine Unlearning
| Our research delves into the critical challenge of data privacy and compliance with emerging regulations, specifically the EU’s General Data Protection Regulation (GDPR). Large AI models have shown tendencies to either hallucinate or inadvertently memorize training data, posing a significant threat to user privacy. In light of GDPR’s ”right to be forgotten”imperative, the necessity to eradicate any traces of sensitive user information is evident. Retraining models from scratch for each individual removal is impractical due to the substantial time and computational resources involved.This research centers on developing an efficient unlearning method, both in terms of time and memory, to effectively eliminate sensitive user data. These unlearning methods can extend their utility to the removal of noisy data points and the mitigation of hate speech. |
Solving Dynamic Programming questions using Integer Optimisation
 | Dynamic programming are a set of algorithms that are applied to reduce the time complexity with memoization. We will pick 3 problems and walk step by step to improve the time complexity. The common aspect of the below problems is that the problem are explicitly to optimize some parameter either number of coins in coin change or profit in knapsack. |
Constrained Optimisation
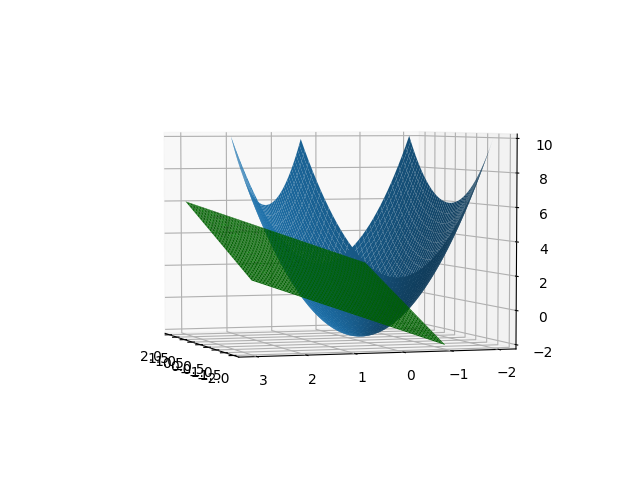 | Fairness problems can be modeled as constrained optimisation problems. One general notion is Minimise the loss of the desired loss function with constrainsts such as it should be fair to all the subgroups. We can define fair in mulitple ways, one such notion is demographic parity should be same for all subgroups. We cover various constrained optimisation techniques covering preliminaries of legrangian method of multipliers and move on to the adverserial min max problems. |